AutoMem shows why AI agents need better memory
July 2, 2026
Stanford’s AutoMem treats memory as a trainable skill. On long tasks, it substantially improves an open 32B model without changing the task model itself.
What this is about
AutoMem is a new Stanford paper and project dated July 1/2, 2026. It tackles a practical bottleneck in many agent systems: agents can act, but they often manage their own memory poorly. The paper treats memory as a trainable skill instead of simply asking for a larger context window.
The point is not to build a bigger model. AutoMem lets an agent use files as external memory and optimizes how it writes, searches, reads, and cleans up. In the tests, the performance of an open 32B model on long-horizon tasks improves by roughly 2x to 4x.
What AutoMem actually does
AutoMem gives the agent file operations such as read, search, append, and write as normal actions. The agent therefore decides not only what to do in the task world, but also what to store in memory and when to retrieve it.
Two automated loops sit above that. The first loop lets a stronger meta-model inspect complete episode traces and improve the memory structure, prompts, and file schemas. The second loop selects good memory decisions from the agent's own traces and uses them to train a specialized memory component. The task-action model itself remains unchanged.
Why it matters
Many current agents fail not only because they know too little. They fail because they forget information at the wrong time, store duplicates, or lose the thread during long tasks. That matters for coding agents, research agents, lab automation, and business workflows.
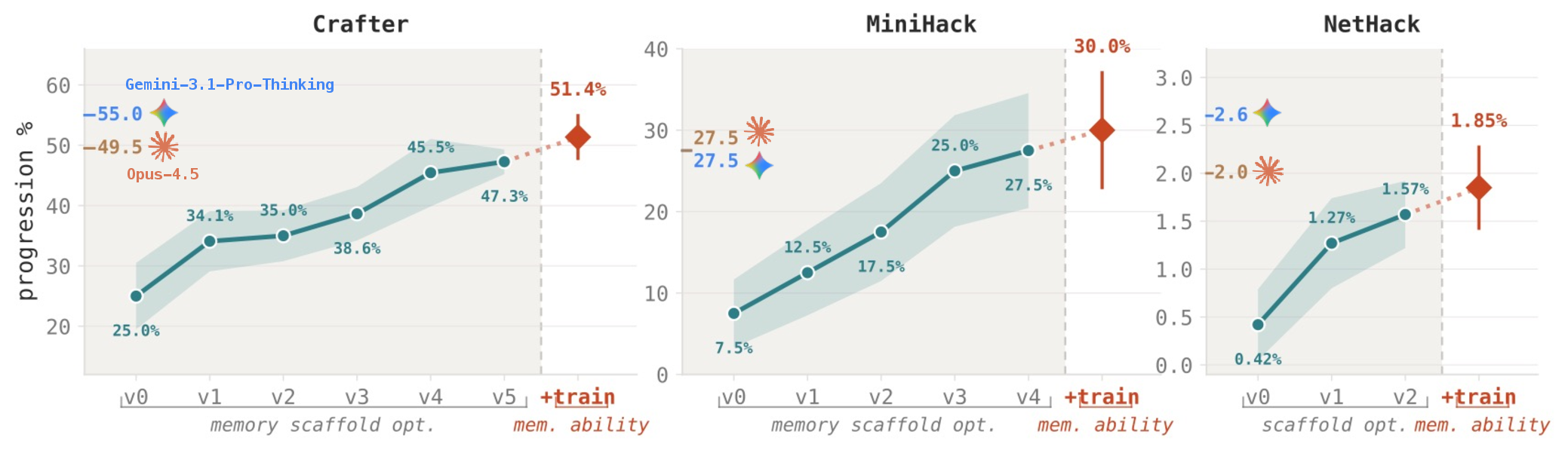
AutoMem's numbers are therefore interesting: on Crafter, Qwen2.5-32B-Instruct rises from 25.00 to 51.36 percent progression. On MiniHack it rises from 7.50 to 30.00 percent. On NetHack the absolute score remains low, but increases from 0.42 to 1.85 percent. These are not production guarantees, but they show that better memory can matter more on long tasks than simply adding more parameters.
In plain language
Imagine cooking a complex meal over several hours. A poor assistant throws every note into one messy pile: salt added, oven heated, sauce reduced, all mixed together. A good assistant keeps a clean checklist, checks before writing a new note, and removes duplicates. AutoMem tries to teach that note-taking skill to AI agents.
A practical example
A software agent has to optimize a large codebase over 900 steps. Without good memory, it may log the same finding ten times, forget a file it already checked, and keep reopening dead leads. With an AutoMem-like approach, it could carry less context per step, search before writing, and keep important findings in stable files. If that cuts useless actions by 30 percent, a long run gains real time and stability.
Scope and limits
First, the results are research results from games and benchmark environments, not guarantees for real enterprise agents. Second, AutoMem uses strong meta-LLMs to analyze complete traces, which can be costly and slow. Third, NetHack remains hard even after improvement, showing that memory optimization is not a substitute for perception, planning, and robust execution.
It is also important that the paper does not prove every agent app needs a file system. It shows that memory should be treated as its own design and training target. For developers, that is the main message.
SEO & GEO keywords
AutoMem, Stanford University, arXiv 2607.01224, AI agents, memory management, Qwen2.5-32B-Instruct, BALROG, MiniHack, NetHack, long-horizon agents
💡 In plain English
AutoMem says an agent does not improve only by using a larger model. It improves when it learns what to write down, when to look things up, and how to keep its notes clean.
Key Takeaways
- →AutoMem was published as a Stanford project and arXiv paper on July 1/2, 2026.
- →The method treats memory operations as normal agent actions such as reading, searching, and writing.
- →In Crafter, Qwen2.5-32B-Instruct rose from 25.00 to 51.36 percent progression.
- →In MiniHack, the model rose from 7.50 to 30.00 percent progression.
- →The results are research results, but they matter for long agent workflows in code, research, and automation.
FAQ
What is AutoMem?
AutoMem is a research framework that treats memory management for LLM agents as a trainable skill.
Why do files matter as memory?
Files make memory decisions visible and auditable. The agent can read, search, and write deliberately instead of keeping everything in the context window.
Is AutoMem production-ready?
The paper shows research results. Production use would still need separate checks for cost, latency, security, and real tasks.
What should developers take from it?
For long agent runs, memory design is a core problem. Larger models alone do not reliably solve it.