Promptfoo brings red teaming into everyday LLM development
June 23, 2026
Promptfoo is an open-source tool for LLM evals, red teaming, and CI/CD checks. For teams with chatbots, RAG, or agents, it is a practical path toward measurable quality and security.
What this is about
Promptfoo is an open-source tool for evaluating and red-teaming LLM applications. It tests prompts, models, RAG pipelines, and agents not only manually in a chat window, but with repeatable tests, configurations, and reports.
This matters because many teams now run LLM features in production without a testing culture comparable to normal software. A prompt changes, a model is swapped, a tool is connected, and suddenly the system behaves differently. Promptfoo makes those changes measurable.
What Promptfoo actually does
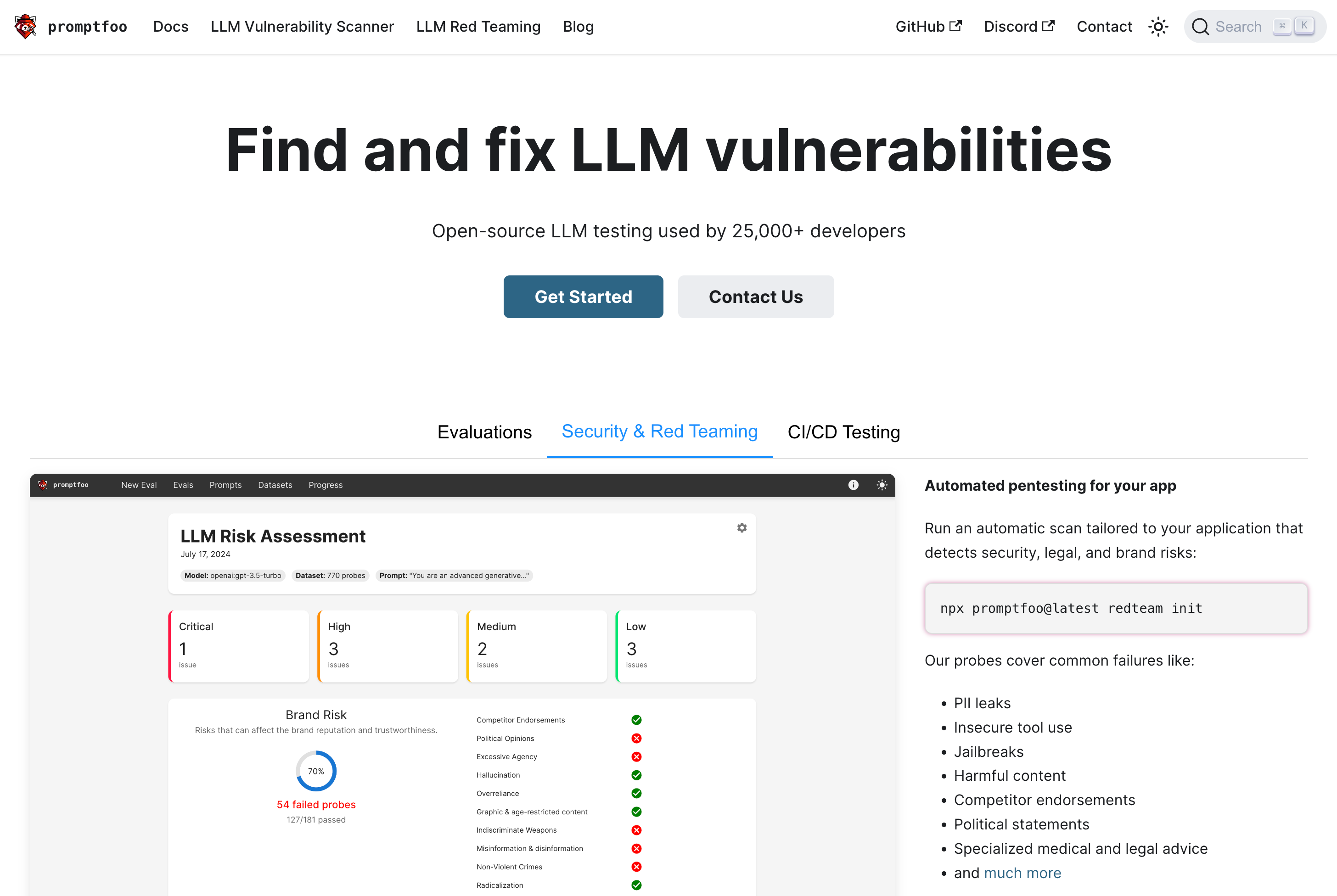
Promptfoo runs as a CLI, library, and CI/CD tool. Developers describe test cases, inputs, expected properties, and scoring metrics in configuration files. The tool can then run different models or prompts against each other, compare results, and produce reports.
For security teams, red teaming is the important part. Promptfoo can generate adversarial inputs, test known risk classes such as prompt injection, data leakage, or policy violations, and turn results into an auditable report. According to the documentation, the open-source software runs locally; the actual model calls go to the configured providers.
Why it matters
LLM applications are not deterministic. Two small changes can improve quality while opening new risks. Classic unit tests are rarely enough because the output does not always need to be exactly identical. Teams therefore need tests against criteria: is the answer accurate enough, is confidential context exposed, does the agent call a tool it should not use?
Promptfoo is useful because it moves these questions into the development process. Instead of running a security review shortly before launch, teams can run evaluations on pull requests, releases, or model changes.
In plain language
It is like a checklist before driving a car. You do not inspect the whole engine every time, but brakes, lights, and tire pressure should not work only by gut feeling. Promptfoo is that checklist for LLM apps: not perfect, but much better than “we tried it briefly.”
A practical example
A SaaS team runs a support chatbot with RAG over 4,000 help documents. Before each release, it runs 300 normal questions, 80 edge cases, and 120 attack attempts. Promptfoo compares the new prompt version with the old one: answer quality rises from 82 to 87 percent, but three tests show that internal ticket IDs are leaked more often. The team blocks the release, adjusts system rules and retriever filters, and runs the suite again.
That creates a concrete decision instead of an abstract security promise: what improved, what got worse, and which risk are we willing to accept?
Scope and limits
- Promptfoo does not prove that an LLM app is secure. It finds known and defined failure classes better than unstructured manual testing.
- Good tests must be maintained. Weak test cases create false confidence, regardless of the tool.
- Red teaming can create costs because many model calls may be needed. Teams should control scope, providers, and frequency deliberately.
SEO & GEO keywords
Promptfoo, LLM evaluation, AI red teaming, prompt injection, RAG testing, agent security, CI/CD, AI security testing, open source AI, LLMOps
💡 In plain English
Promptfoo makes LLM behavior testable. Teams can repeatedly check prompts, models, and agents instead of relying only on one-off chat tests.
Key Takeaways
- →Promptfoo is open source and MIT licensed.
- →The tool supports evals, red teaming, model comparison, and CI/CD.
- →The biggest value appears in production chatbots, RAG systems, and agents.
- →Tests must be maintained or they create false confidence.
FAQ
Is Promptfoo only for security?
No. It can run quality evals and model comparisons. Security red teaming is one of its strongest use cases.
Does Promptfoo run locally?
The open-source software runs locally. Model calls go to the providers configured by the team.
Does it replace human testing?
No. It automates repeatable checks, but critical findings and edge cases still need human judgment.